1.5. Design Example: GSM Vocoder
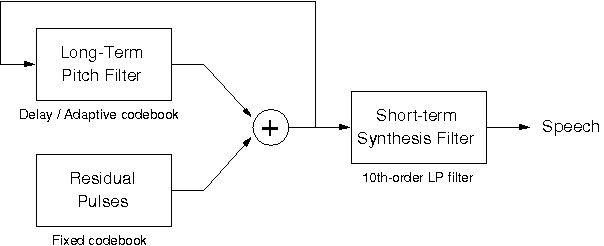
The example design used throughout this tutorial is the GSM Vocoder system , which is employed worldwide for cellular phone networks. Figure 1-2 shows the GSM Vocoder speech synthesis model. A sequence of pulses is combined with the output of a long term pitch filter. Together they model the buzz produced by the glottis and they build the excitation for the final speech synthesis filter, which in turn models the throat and the mouth as a system of lossless tubes.
The example used in this tutorial encodes speech data comprised of frames. Each frame in turn comprises of 4 sub-frames. Overall, each sub-frame has 40 samples which translate to 5 ms of speech. Thus each frame has 20 ms of speech and 160 samples. Each frame uses 244 bits. The transcoding constraint (ie. back to back encoder/decoder) is less than 10 ms for the first sub-frame and less than 20 ms for the whole frame (consisting of 4 sub-frames).
The vocoder standard, published by the European Telecommunication Standards Institute (ETSI), contains a bit-exact reference implementation of the standard in ANSI C. This reference code was taken as the the basis for developing the specification model. At the lowest level, the algorithms in C could be directly reused in the leaf behaviors without modification. Then the C function hierarchy was converted into a clean and efficient hierarchical specification by analyzing dependencies, exposing available parallelism, etc. The final specification model is composed of 9139 lines of SpecC code, which contains 73 leaf behaviors.